Animint
Anime & manga
Comment le monde a été sauvé...ou pas : L'affaire de la tz database
Publié par Pazu le 14 mars 2012 18:46 dans Webmastering :: 2 commentaires »

Je change de registre pour passer de mes centres d'intérêt nippons à un sujet plus orienté vers les nouvelles technologies.
Je n'apprendrai rien à ceux qui suivent un minimum les actualités dans le domaine mais à l'intention des autres : Saviez-vous que nous avons échappé à la fin du monde en octobre dernier? Oui comme ça, sans prévenir alors que vous surfiez sur internet ou tapotiez sur votre i-phone à ce moment là, un cataclysme interplanétaire ? n'ayons pas peur des mots ? est survenu le 6 octobre 2011 : La tz database a été fermée.
Discuter de ce billet sur le forum - Laisser votre commentaire »
Wall Sama : Un exercice d'utilisation des API Facebook et Twitter
Publié par Pazu le 15 février 2012 12:51 dans Webmastering :: 3 commentaires »
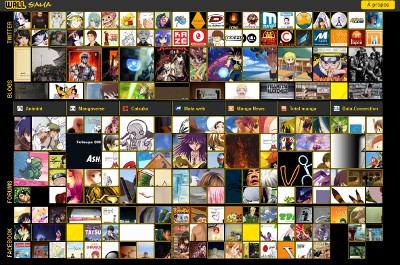
Dans la lignée d'Aggregator Sama, l'agrégateur de blogs et de ses émulations expérimentales sous forme de journal ou de magazine en ligne, j'ai étendu les sources d'informations à des réseaux sociaux, avec une présentation purement visuelle, pour bâtir Wall Sama, un mur d'images, rafraichi régulièrement. Je vous laisse découvrir par vous-mêmes et trouver une quelconque utilisation à cet exercice de style, qui m'a permis de me familiariser avec les interfaces fournies par Twitter et Facebook.
J'avais déjà abordé le sujet pour Facebook, avec la mise en place d'une application, émulation de la base encyclopédique, qui m'avait incité à revoir les fonctionnalités sur Animint. L'abandon par Facebook, à bon escient, de leurs tags HTML propriétaires m'a forcé cependant à revoir mes ambitions à la baisse pour remettre en ligne une application épurée, encapsulée dans son iframe.
Discuter de ce billet sur le forum - Laisser votre commentaire »
Le top 2011 des sites web des éditeurs mangas
Publié par Pazu le 23 décembre 2011 19:07 dans Webmastering :: Aucun commentaire »

En cette période de fêtes, vous échappez à un traditionnel classement des meilleurs anime de l'année mais à la place, vous héritez d'un top 2011 des sites web des éditeurs mangas. L'idée me trotte dans la tête depuis quelques temps, à force de passer par ces sites particuliers pour compléter les sorties de mangas sur Kelmanga. Quand vous consultez les plannings et les fiches régulièrement, vous finissez par discerner les qualités et les défauts des uns et des autres.
Si j'avais effectué la même analyse à la fin 2009, j'aurai vilipendé les trois quarts des éditeurs pour le manque d'attention apporté à leur vitrine sur le net, que ce soit pour des choix de design abracadabrants ou bien une ergonomie défaillante, quand ce n'était pas un abandon pur et simple du contenu, comme c'est malheureusement le cas chez certains éditeurs vidéos à l'heure actuelle.
Depuis, la situation a changé, avec des efforts pour abandonner les structures obsolètes dignes des années 90, remplacées par des pages plus en phase avec le web 2.0 et de l'omniprésence des réseaux sociaux. En ce sens, l'année écoulée est assez représentative avec la refonte des sites de Panini Comics, Kana ou encore Kurokawa.
Discuter de ce billet sur le forum - Laisser votre commentaire »
La blogosphère analysée via la théorie des graphes
Publié par Pazu le 26 août 2011 23:02 dans Webmastering :: 21 commentaires »
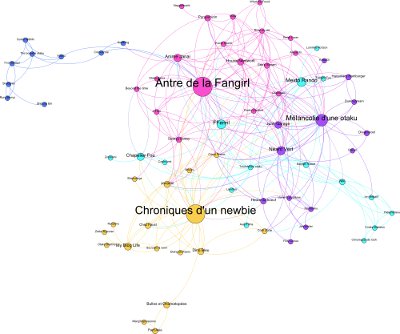
En décembre 2010, vous avez découvert une carte des sites internet français de japanimation, qui, à l'occasion, sera à mettre à jour et à compléter. Sa conception a été très empirique, en prenant en compte les sous-thèmes des sites web et en sentant leur importance à vue de nez. Il existe cependant des méthodes plus objectives pour représenter les réseaux, notamment grâce à la théorie des graphes.
Je me suis lancé en partant de blogs pour la plupart inscrits sur Aggregator Sama, avec un graphe basé sur les liens sortants d'un site à l'autre. Je n'ai pas décortiqué en détail toutes les pages, mais noté rapidement le contenu des blogrolls et des autres pages similaires. Chaque point du graphe est un site et dans le schéma, le site A est lié au site B, si A a au moins un lien web vers B. Le graphe est orienté étant donné que les liens ne sont pas forcément réciproques.
A partir de là, vous obtenez les données brutes du graphe des blogs, de manière simpliste, avec des liens de poids équivalents. Ensuite, un outil tel que Gephi permet de lancer une succession de traitement pour analyser l'ensemble.
Discuter de ce billet sur le forum - Laisser votre commentaire »
Sama Mag - La blogosphère en un clin d'oeil
Publié par Pazu le 20 août 2011 16:09 dans Webmastering :: 4 commentaires »
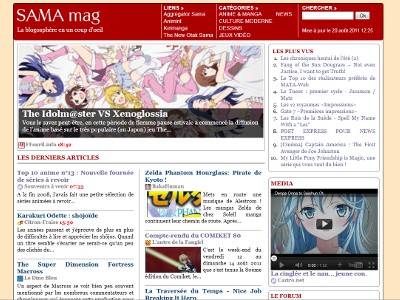
Aggregator Sama lit les flux de nombreux sites de la blogosphère otake francophone et le site extrait une sélection d'articles, avec des fonctionnalités annexes, diverses et variées, de la personnalisation des flux à la navigation par tags. Il fait son travail mais son aspect se calque sur les logiciels de lecteur de flux et j'ai voulu obtenir une présentation plus orientée site web classique. Vous aviez la version du New Otak' Sama et voici maintenant le Sama Mag.
Le principe est de piocher les articles dans la base de l'agrégateur et de les classer dans les différentes rubriques de la page au format magazine. Dans le lot, vous avez la une de la page, une liste des billets les plus récents, et les derniers écrits, catégories par catégorie, sans oublier les tops des articles. A cela s'ajoute une vidéo extraite de l'un des articles, une widget qui affiche les tweets d'auteurs référencés, un nuage de tags, et quelques blogs sources sous forme de miniatures.
Discuter de ce billet sur le forum - Laisser votre commentaire »
Anniversaire des 4 ans pour Sama : Agrégateur et Awards
Publié par Pazu le 19 juin 2011 18:48 dans Webmastering :: 5 commentaires »

La date anniversaire du lancement d'Aggregator Sama est l'occasion de dresser un états des lieux, avec quelques réflexions sur l'outil, et d'étendre mes propos avec mon bilan des Sama Awards.
Commençons l'état des lieux avec les statistiques, limitées aux visites par le web ? je n'ai toujours pas regardé ceux qui passaient uniquement via les flux RSS. Sur les 30 derniers jours, cela donne un peu plus de 12 000 visites et plus de 1 800 visiteurs uniques, pour 70 sites actifs et 500 articles récoltés. Un 5ème des visites proviendrait des moteurs de recherche, un quart depuis d'autres blogs et le reste se fait directement via les favoris ou en tapant l'adresse du site. L'Antre de la fangirl est le 2ème site (2%) derrière Animint (4%) qui draine des visiteurs sur Aggregator Sama, juste devant twitter.
Discuter de ce billet sur le forum - Laisser votre commentaire »
Le site Animint a 15 ans
Publié par Pazu le 19 mai 2011 18:41 dans Webmastering :: 13 commentaires »
L'adaptation en anime de Détective Conan est à peine plus âgée. Pour les 10 ans du site, j'avais enregistré un podcast avec une rétrospective sur la décennie écoulée et notamment des indications sur l'historique d'Animint.
Si vous avez déjà écouté ce podcast, cela doit donc faire au moins 5 ans que vous connaissez ce site
Pour les 15 ans, je vous propose de délaisser l'audio pour privilégier le visuel et de parcourir les différents designs du site.
Je me suis replongé dans les sauvegardes ponctuelles effectuées au fil du temps, pour effectuer quelques captures d'écran.
Discuter de ce billet sur le forum - Laisser votre commentaire »
Motivation, vous avez dit motivation?
Publié par Pazu le 21 décembre 2010 15:41 dans Webmastering :: 43 commentaires »

Au travail, c'est un sujet récurrent pour les managers qui doivent mobiliser la matière grise de leurs collaborateurs ou travailler dans le cadre d'un projet avec d'autres personnes. Au delà des méthodes plus ou moins morales, les formateurs aiment bien aborder le thème en mettant un pied dans la psychologie et vous sortir des mots savants, tels que la pyramide des besoins de Maslow. La hiérarchisation des besoins est simple à saisir ? ça tient bien sur un slide de présentation Powerpoint ? mais pour le moins éculé. Cela date de 1954 quand même et bien remis en question depuis. Néanmoins, vous avez là une idée simple de classification de vos aspirations et où vous en êtes.
Discuter de ce billet sur le forum - Laisser votre commentaire »
Une cartographie des sites internet français de japanimation
Publié par Pazu le 15 décembre 2010 22:25 dans Webmastering :: 16 commentaires »
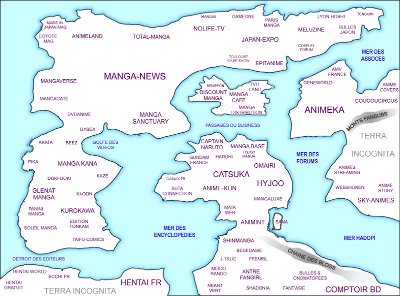
Voici une représentation de l'esprit, vu du ciel, du monde des sites internet de japanimation, en remplaçant la toile par des continents et des océans, et les sites par des contrées.
Les pays proches représentent des thématiques similaires et la taille de la région reflète l'importance du site.
La sélection des sites s'est faite selon la notoriété et aussi à partir de certaines requêtes lancées sur Google. J'ai normalement privilégié les sites actifs par rapport à des mastodontes en hibernation, tels que Cyna, qui n'apparait pas. Il peut y avoir des oublis involontaires mais passé un certain point, le choix de faire apparaître ou non certains sites est vite devenu arbitraire. Il n'y a malheureusement pas la place de tout mettre, notamment pour les sites spécifiques à une série.
L'importance donnée aux sites est empirique. La panoplie d'outils internet publics pour évaluer la fréquentation et les nombre de liens entrants donne des résultats pour les moins très aléatoires donc inutile de compter dessus, même si une certaine constance émerge finalement pour quelques sites phares.
Cliquez sur l'image pour l'agrandir.
Discuter de ce billet sur le forum - Laisser votre commentaire »
Récapitulatif des services sur Animint
Publié par Pazu le 27 septembre 2010 21:11 dans Webmastering :: 2 commentaires »

En apercevant le commentaire de Corti, je me suis dit qu'un petit tour d'horizon des différents services disponibles sur Animint n'était peut être pas inutile. Je travaille techniquement sur quelques rubriques en priorité car elles contribuent au plan machiavélique de conquête de l'univers projet d'évolution générale du site pour se remettre au goût du jour. A contrario, je délaisse certaines fonctions mais elles tournent toujours, donc autant les citer.
Les interfaces
J'entends par interface, les différents moyens pour accéder au contenu du site, via un autre biais que le navigateur web classique.
Discuter de ce billet sur le forum - Laisser votre commentaire »